
두 개의 독립변수에 따른 종속변수의 평균 차이, 이원 분산분석
이원분산분석(Two way Anova)은 두 개의 독립변수에 따라 집단 간 종속변수의 평균 차이를 비교 검정 하는 방법입니다.
이원 분산분석 결과는 처치효과로 주효과와 상호작용효과를 보여주고, 두 개의 독립변수 간 관계에 따라 두 가지로 구분합니다.
*주효과는 독립변수들이 각각 독립적으로 종속변수에 미치는 영향을 검정하는 것인데, 즉 한 처치변수의 변화가 결과변수에 미치는 영향을 말합니다.
*상호작용효과는 독립변수들이 서로 연관되어 종속변수에 미치는 영향을 검정하는 것인데, 즉 다른 처치변수의 변화에 따라 한 처치변수가 결과변수에 미치는 영향에 관한 것입니다.
예를 들어 이원분산분석을 실시해 볼게요.
독립변수는 2개의 범주형 자료, 종속변수는 연속형 자료가 되어야 합니다.
A회사가 신제품 광고로 세 가지 광고 대안을 기획하고, 피실험자들에게 노출시킨 다음 광고태도를 측정하여 소비자들이 좋아하는 광고를 선택하고자 한다고 가정할게요.
마케팅 기획 담당자는 광고 대안 기획들에 대한 태도가 성별에 따라 다를 것이라 생각하고 어느 집단이 더 좋아할까를 알고 싶어합니다.
실험은 남녀 각 9명의 피실험자들을 6개의 셀에 할당하고 각 피실험자에게 세 가지 광고 중 하나를 보여줍니다.
점수는 0~5점 까지 0.1간격으로 체크한 후 태도 결과 점수는 다음과 같이 나왔다고 가정합니다.

따라서 가설은 다음과 같습니다.
1. 광고대안에 따라 광고태도가 다를까?
2. 성별에 따라 광고태도가 다를까?
3.성별과 광고대안 간에 상호작용효과가 있을까?
SPSS에서 분석-일반선형모형-일변량 클릭
변수목록에서 태도점수 클릭 - 종속변수로 이동 - 광고와 성별 클릭 - 모수요인으로 이동
- 도표 - 광고 선택(요인분석창) - 수평축변수로 이동 - 성별 선택(요인분석창) - 선구분변수로 이동 - 추가
- 사후분석 클릭 - 광고 선택(요인분석창) - 사후검정변수로 이동 - 사후분석방법 (Bonferroni(B), Tukey방법(T), Scheffe(C)체크)
- 옵션 클릭 - 기술통계량과 주효과크기추정값 체크 - 계속 클릭 - 확인 클릭

<개체 간 효과 검정>결과표를 보면 태도 점수에 대한 광고 대안과 성별의 주효과, 두 변수의 상호작용효과가 나타납니다.
먼저, 상호작용효과를 보면 F=1.344, 유의확률(p-value)=.297로 나타나
"광고대안과 성별은 상호작용효과가 없는 것"으로 확인됩니다.

<도표>는 상호작용효과를 보여주는데 두 개의 선이 나란히 나타나 상호작용 효과가 없다는 것을 보여주고 있습니다.
상호작용효과가 유의하지 않기 때문에 성별에 따라 광고 대안들에 대한 태도의 패턴이 다르다고 할 수 없죠.
여기서 잠깐~~~~!!

이원배치 분산분석에서 그래프가 꼭 X자로 교차해야 할까요?
교차하지 않아도 두 직선의 기울기 차이가 매우 크다면 상호작용 효과는 유의하게 나타납니다.
그럼 그래프가 X자로 교체되었다고 꼭 상호작용 효과가 있을까요?
교차되더라도 두 직선의 기울기가 매우 작다면 두 변수의 상호작용 효과는 유의하지 않게 나타납니다.
즉, 그래프 보다 상호작용 변수의 p값이 유의수준(.05) 보다 작다면 상호작용효과는 유의한 것입니다.

다음으로 광고 대안의 주효과를 보면, F=21.811, 유의확률(p-value)=.000으로 나타나
"광고대안에 따라 태도점수에는 차이가 있는 것"으로 확인됩니다.
<기술통계량>을 확인해보면 결국, 태도점수는 광고1(3.45), 광고3(2.97), 광고2(2.60)의 순이 됩니다.
다음으로 성별의 주효과를 보면, F=100.278, 유의확률(p-value)=.000으로 나타나
"성별에 따라 태도 점수에는 차이가 있는 것"으로 확인됩니다.
<기술통계량>을 확인해보면 결국, 남자들의 태도점수(3.533)가 여자들의 태도점수(2.48)보다 높습니다.
<개체 간 효과검정>의 결과표에 부분 에타 제곱값은 효과크기를 나타내는 값이에요.
분산분석에서 효과크기는 집단 간 평균 차이를 나타내는 표준치에요.
분산분석에서 효과크기를 판단하는 값인 부분에타제곱의 값이 .01이면 효과크기가 작고, .06이면 중간, .14이면 크다고 판단합니다.
위 표에 상호작용효과의 부분에타제곱값이 .183으로 비교적 크다고 할 수 있습니다.
그런데 효과크기가 큼에도 불구하고 유의하지 않은 결과가 나온것은 표본의 크기가 각 셀당 3개씩 너무 작기 때문이에요.
따라서 표본의 크기가 커질수록 분석결과가 통계적으로 유의하게 나타나고 통계적 검증력 또한 커질 것으로 짐작할 수 있죠.
광고와 성별의 주효과의 부분에타제곱은 각 .784, .893으로 매우 큽니다.
<개체 간 효과검정>의 최하단에 있는 R제곱은 두 개의 처치변수와 그 상호작용이 종속변수의 분산을 설명하는 정도를 나타냅니다.
이 경우 두개의 주효과에 관련된 제곱합과 상호작용효과에 관련된 제곱합을 더한 값(2.181+5.014+.134)을 수정합계 값(7.329)로 나누면 값이 .924가 되죠.
즉, 수정모형의 부분에타제곱값에 해당하고, 이는 회귀분석의 R2(알스케어)에 비유될 수 있어요.

<다중비교>는 세 집단의 태도값들 간의 사후검증결과를 나타냅니다.
광고1-광고2, 광고2-광고3, 광고1-광고3의 비교 결과 세 가지 방법 모두에서 유의한 차이를 보였습니다.
사후검증에서는 Tukey법에 의한 차이가 가장 유의적으로 나타났어요.
광고1-광고3을 보면 Tukey는 .007, Scheffe는 .010, Bonferroni는 .008이 확인되죠?
그리고 Tukey법에 의한 신뢰구간이 가장 좁아요.
이러한 결과는 각 Cell의 크기가 같은 경우 Tukey법을 사용한다면 집단 간 차이를 가장 정밀하게 감지하는 장점이 있습니다.


이번에는 다른 예를 들어 보도록 하겠습니다.
성별과 배달앱 브랜드(A,B,C사)가 선호도에 미치는 영향에 대하여 알아보겠습니다.
선호도는 9점 리커트 척도를 사용한 것으로 가정합니다.
가설은 다음과 같습니다.
1.배달 앱 브랜드에 따라 선호도에 유의한 차이가 있다.
2. 성별에 따라 선호도에 유의한 차이가 있다.
3. 선호도에 대하여 성별과 배달앱 브랜드 간에 유의한 상호작용 효과가 있을 것이다.
좀 전 분석해 본 방법과 약간 다른 방식으로 해보겠습니다.
분석방법은 위와 동일합니다.
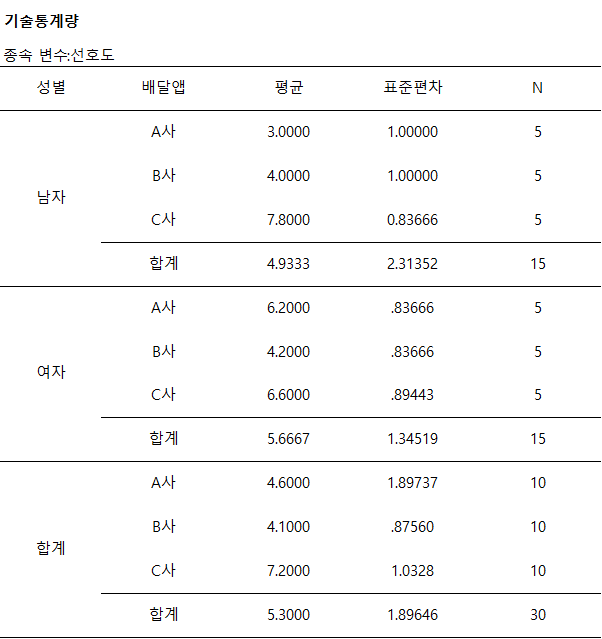



이원 분산분석 결과 상호작용효과와 두 개의 주효과는 모두 .05수준에서 유의적으로 확인되었습니다.
X축을 배달앱 Y축을 선호도로 하여 그림을 그려보면 남자와 여자의 선이 서로 교차하여 상호작용 효과가 있음을 알 수 있어요.
개체간 효과검정에도 유의하게 나오죠.
특히 배달앱 A사의 경우 남자들의 선호도보다 여자들의 선호도가 매우 높으며 이에 따라 상호작용효과가 크게 나타난 것으로 판단됩니다.
주효과와 상호작용효과의 효과크기(부분에타제곱)은 모두 큰 것으로 확인되었습니다.
다중비교를 보면, 선호도는 A와 C사, B사와 C사가 유의한 차이를 보이고, A사와 B사는 유의한 차이를 보이지 않네요.
대소 관계를 표현한다면, C사 < B사, A사 라고 할 수 있습니다.
퀵데이터는 여러분의 성공을 위해 오늘도 함께 하겠습니다~~^^
(주)한국교육데이터



'논문' 카테고리의 다른 글
| 독립표본t검정 '퀵데이터'에서 자세히 알아보아요^^ (0) | 2020.08.12 |
|---|---|
| 대응표본 t검정 '퀵데이터'에서 알아보기 (0) | 2020.08.12 |
| 일원분산분석이란 무엇일까요?_퀵데이터 (0) | 2020.08.12 |
| 반복측정 분산분석!! 퀵데이터에서 알아보기 (0) | 2020.08.03 |
| 구조방정식(AMOS)을 이용한 매개효과 분석_CEO 오센틱리더십과 학습조직이 조직유효성에 미치는 영향_심리자본 매개효과_퀵데이터 (0) | 2020.08.03 |



