”군집분석란 무엇인가요?“
“논문 작성할 때 군집분석 및 해석은 어떻게 해야 하나요?”
“논문에서 사용되는 군집분석은 어떤 분석방법을 이용해야 하나요?”
”논문 작성할 때 군집분석은 어떻게 활용해야 할까요?“
“군집분석의 계층적 군집, 비계층적 군집 분석의 차이는 뭔가요?”

"통계분석을 위한 군집분석 튜토리얼: 대학원생 논문작성을 위한 실전 가이드"

▣ 대학원생의 전공 필수과목과 선택과목 성적에 따른 군집 분류
■ 계층적 군집분석 방법


1번 학생과 2번 학생의 필수, 선택 과목 성적에서 1은 필수가 100점이고 2는 66점일 때 34점의 차이가 있다. 그리고 1번 학생은 선택이 83점이고 2번 학생은 66점일 때 17점의 차이가 있다. 이런 차이는 1번 학생과 2번 학생의 각 성적에 대한 상이성 정도이다. 이렇게 비교 대상이 되는 변수 간 차이의 제곱을 합산해서 상이성의 정도를 측정하는 것이 제곱 유클리드 거리이고 가장 흔하게 사용되는 방법이다. 지금 보는 근접행렬의 표 값이 제곱 유클리디안 거리이다.

- 관측대상(케이스) 간의 제곱 유클리디안 거리 행렬이고 이 값들은 비유사성 자료이므로 작은 값을 가질수록 유사성이 높음
고드름 도표는 계층적 군집분석의 단계별 군집화 과정을 시각적으로 파악할 수 있다. 그러나 단계별 군집화 과정을 시각적으로 잘 표현해 주긴 하지만 각 단계에서 새로운 군집이 생성될 때 대상이 되는 두 군집 간의 거리가 얼마인지 알 수 없다. 이런 정보를 추가로 제공해 주는 것이 군집화 일정표이다.

- 고드름도표(Icicle plot)는 최종 군집 수에 따라 어떤 케이스들이 군집화 되었는가를 나타냄
- 위 도표를 볼 때 케이스 (11,10,6), (9,8,7,3,2), (4,12,5,1)로 군집화 됨
군집화 일정표는 단계별로 군집이 형성되는 과정을 체계적으로 보여주긴 하지만 데이터가 많지 않으면 고드름 도표를 보는 것이 군집화 과정을 이해하기 더 쉬울 수 있다. 군집화 일정표는 상이성 혹은 유사성 계수를 확인하는데, 주로 활용된다.

- 계수값의 증가는 그 단계의 군집화에 의해 케이스의 이질성이 급격히 커짐을 의미
- 계수값이 9단계에서 10단계로 오면서 약 3배 이상 증가하고 11단계에서도 크게 증가함
- 따라서 3개의 군집으로 구분할 수 있지만, 더 자세하게 구분하는 것은 덴드로그램 이용
데트로그램상에서는 실제로 거리는 확인할 수 없지만, 조정된 척도의 비율은 실제 거리의 비율과 같기 때문에 군집 결합 시 기준이 되는 군집 간 거리의 상대적 차이는 알 수 있다. 즉, 군집의 개수를 정하기 위한 가이드라인으로 활용된다.
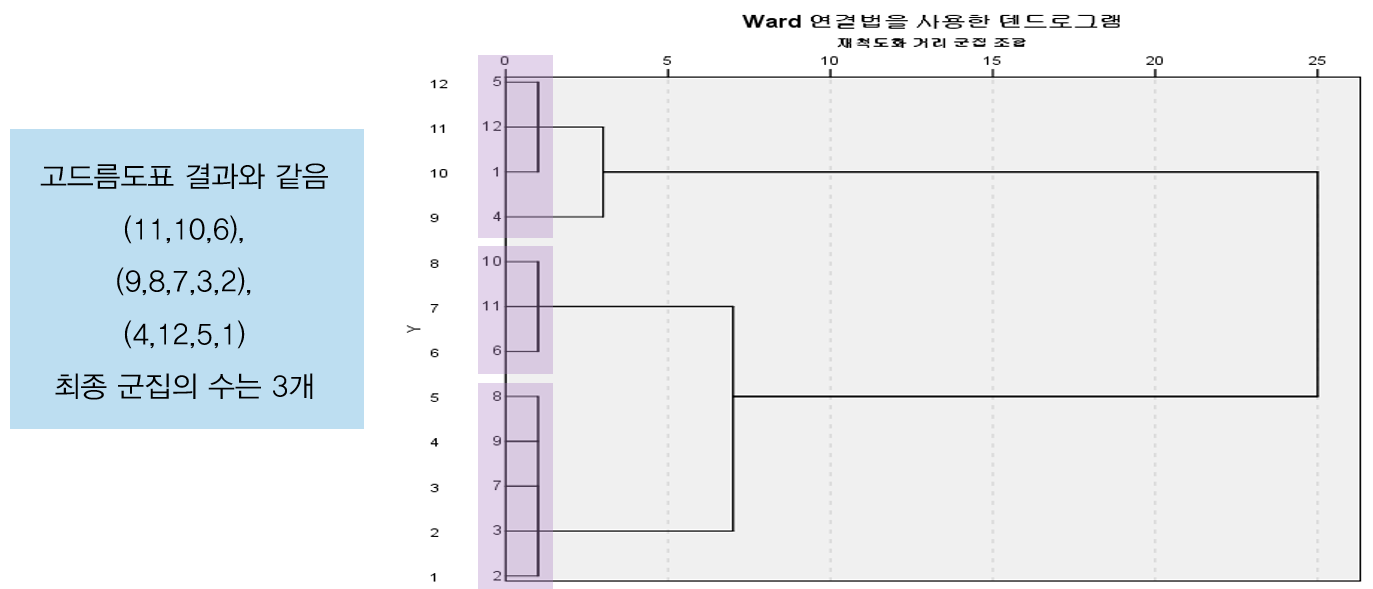
- 덴드로그램은 케이스들이 군집화되는 과정을 그림으로 나타냄
- 세로축에는 최초의 군집(하나의 케이스로 구성된 군집)이 나열되어 결합되어 가는 과정을 보여줌
- 가로축은 군집이 결합될 때의 거리(군집화 일정표의 계수에 해당)가 원래 거리값이 아닌 1~25사이의 값으로 척도가 조정된 값으로 보여줌
■ 비계층적(K평균) 군집분석 방법
K평균 군집분석은 원하는 군집의 개수를 미리 사전에 알고 있어야 한다. 군집 개수를 변경해가면서 여러 번 실행하면 되지만 보통 계층적 군집분석으로 군집 개수를 확인하고 K 평균 군집분석을 사용한다. 계층적 군집분석에서는 군집화를 위해 모든 케이스 간의 상이성 또는 유사성을 측정해야 하는데 케이스가 많으면 근접행렬이 매우 커지게 되고 군집 판단의 어려움도 있다. 반면, K 평균 군집분석은 모든 케이스 간의 상이성이나 유사성 측정을 요구하지 않기 때문에 케이스가 많을 경우는 K 평균 군집분석을 사용한다.

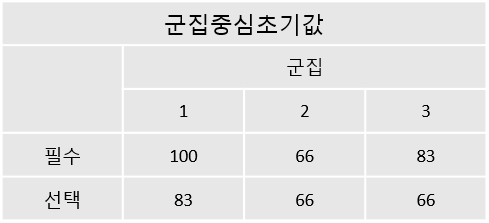
- 12개의 케이스 중 3개의 군집화
- 초기 중심값을 기준으로 각 케이스와 각 군집의 중심점과의 거리를 계산하여 거리가 가장 가까운 군집에 케이스를 할당

- 케이스들이 군집에 모두 할당되고 나면 군집에 포함된 케이스를 이용하여 다시 군집중심이 계산됨
- 이런 과정은 군집중심에 있어 변화가 거의 없거나 미리 설정된 최대반복계산횟수(10회 기본값)에 도달할 때까지 계속
- 표에서는 2회의 반복계산을 거쳐 군집화 과정 종료

- 각 케이스들의 소속군집 확인
- 군집 1에는 (1,4,5,12), 군집2에는 (2,3,7,8,9), 군집3에는 (6,10,11) 할당
- 계층적 군집과 동일하게 군집화

- 3개의 군집에 분류된 케이스의 수
- 1번 군집(4개), 2번 군집(5개), 3번 군집(3개)


통계분석 군집분석 및 해석이 궁금하다면 퀵데이터 논문통계 강의 보기▼▼▼
"논문의 품질을 높이는 열쇠!!!
퀵데이터 논문통계분석을 통해 더욱 탄탄한 논문을 완성하세요."
퀵데이터 논문컨설팅은 논문 주제 선정부터, 연구모형, 통계분석, 심사 준비까지 전문 지도 박사님의 1:1 맞춤형 컨설팅 통해 효율적이고 빠른 논문작성을 도와드립니다. 논문 검토, 논문편집, 논문 통계분석까지 직접적인 컨설팅을 원한다면 퀵테이터에 문의하세요 상담문의 1600-7473
홈페이지 : www.quickdata.co.kr 대표번호 : 1600-7473 e-mail : quickdata7@naver.com




