

오늘은 논문통계에서 사용되는 일원분산분석 및 일원분산분석 해석 방법에 대해 알려드립니다.
spss를 이용한 일원분산분석 및 통계해석, 논문통계작성법까지 논문통계 어렵지 않습니다.


• 독립변수로 구분되는 3개 이상의 각 집단 간 종속변수의 평균들이 통계적으로 유의하게 차이가 있는가를 검정
• 실험 계획법(완전 랜덤법)에서는 한 요인의 종속변수에 대한 효과 파악

완전랜덤계획법은 실험대상 전체에 실험순서 또는 처리배치를 완전히 랜덤으로 정하는 실험법이다. 예를 들어 30명 학생을 대상으로 3가지의 학습법을 비교한다고 가정하자. 첫째 30명 학생들에 대해 고유번호(1~30)를 부여한다. 1번부터 3번까지 적힌 종이를 30명의 학생들에게 뽑게 한다. 1번을 뽑은 학생은 A학습법, 2번은 B학습법, 3법은 C학습법으로 교육하고 일정기간이 지난후 이 학생들을 대상으로 효과를 평가하는 시험을 치른다. 여기서 얻은 시험성적 데이터를 분산분석에 활용한다. 분산분석은 보통 차이가 있다 없다로 결론 내리는데 완전랜덤법을 이용한 실험 데이터일때는 집단 간 차이로 결론 내리는 것 이상으로 어떤 요인이 종속 변수에 영향을 미친다.
• 정규성 검정: 일반적으로 표본이 30 이상일 경우 정규성 만족(중심극한정리)
∨정규성 만족 안될 경우 비모수 검정방법(Shapiro-wilk test(n>30), kolmogorov-smirnov test(n<30))
• 분산의 동질성 검정: Levene의 통계량으로 동질적 집단 여부의 값 표시
유의 확률이 0.05가 넘어가면 동질성이 있다는 뜻 (p > 0.05)
∨ 귀무가설 H0: 각 집단의 분산은 같다(차이가 없다).(σ_1^2=σ_2^2=σ_3^2….. σ_k^2)
∨ 대립가설 H1: 각 집단의 분산은 다르다(차이가 있다).

∨ 귀무가설 H0: 각 집단의 평균은 같다(차이가 없다).(μ_1=μ_2=μ_3…… μ_k)
∨ 대립가설 H1: 각 집단의 평균은 다르다(차이가 있다).
▣ 연구문제1. 4개의 영어 교육법에 따른 학습효과는 차이가 있는가?

spss의 일원분산분석을 이용해 연구문제1에 대한 차이검증을 살펴보면,
• spss에서 분석 – 평균비교 – 일원배치 분산분석
∨옵션: 기술통계, 분산 동질성 검정 클릭
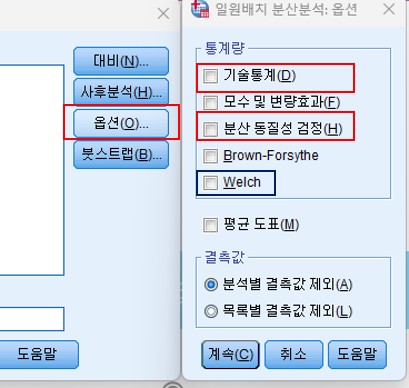
• 등분산이 가정되지 않았을 때 Welch 이용

※ 등분산 가정할 때 집단 간 표본의 크기 고려하여 선택
□ 다중비교(등분산 가정)
• Scheffe, Bonferroni (각 집단(cell)의 크기 무관하게 사용)
• Tukey, Duncan (각 집단(cell)의 크기가 같을 경우)
가장 많이 사용하는 Scheffe는 집단의 차이가 많을 때 주로 사용하는데 예를 들면 A집단에는 100명, B집단에는 60명과 같이 표본이 크게 차이가 나는 경우에 사용된다. Duncun은 샘플의 크기가 같다고 하지만 완전히 같지 않아도 어느정도 일정할 때, 예를 들면 A집단은 100명, B집단은 96명 정도로 표본이 근소하게 차이가 나더라도 사용 가능하다. 대체적으로 보면 Scheffe보다 Duncan이 유의한 결과가 잘 나오는 양상을 보인다.
□ 다중비교(등분산 가정하지 않음)
• Tamhane의 T2 (각 집단(cell)의 크기 무관)
• Dunnett: 대조 집단과 다른 집단 비교 시
• Dunnett (T3): 각 집단 n<50, Dunnett (C): 각 집단 n≥50
• Games-Howell: welch 이용 시 사후검증
분산 동질성을 만족하지 않을 때 분석시 옵션에 있는 Welch를 체크하고, 사후분석도 등분산 가정을 필요로 하지 않는 Tamhane나 Dunnett을 체크해서 분석해 활용한다.

[등분산을 가정함]
∨ Bonferroni : 모든 두 집단간 비교는 t검증을 사용하지만 각 검정에 대한 오차 비율을 조정해서
전체 오차 비율을 제어
∨ Scheffe : 타 검정 대비 보수적인 방법, 두 평균 차이에 대한 유의성을 발견하기가 상대적으로 어려움
∨ Tukey : Tukey의 정직 유의차 검정으로 전체 오차 비율 제어
∨ Duncan : 비교 단계별 순서를 통해 비교를 수행하지만 검정 집합에 대한 오차 비율 제어
[등분산을 가정하지 않음]
∨ Tamhane: T검정을 기준으로 한 보수적 비교 방법
∨ Dunnett: 스튜던트화 최대계수(T3), 범위를 기준으로(C) 사용하는 비교 방법
∨ Games-Howell: 경우에 따라 자유롭게 수행되는 비교 방법
♣ 기본 분석 해석

• 학습효과는 A방법이 가장 높고, D방법이 가장 낮음

• P>.05 : 분산이 동일(p값이 유의확률보다 크기 때문에 분산의 동질성은 만족함)

• 교육방법에 따라 학습효과가 차이가 있다는 결론
• 어떤 교육방법에서 학습효과의 차이가 있는지 검정하기 위해 사후 검증의 다중 비교를 진행
♣ 사후 검정 해석
사후검정은 집단 간 평균값을 비교하고 통계적으로 유의할 때 그 평균값의 크기 비교를 하는 분석이다. 사후분석의 다중비교에 있어서 각 집단의 표본크기가 다른 경우에는 scheffe와 Bonferroni 중 어느 것을 사용해도 된다. 두가지 모두 체크해서 분석해보고 차이를 더 잘 분류하는 것을 택하면 된다.

• A방법과 D방법 간 학습효과 차이는 유의 (유의 확률= .039 / p<.05)
• A방법 – D방법 = .353
⇒ 영어 교육 A방법이 D방법보다 학습효과에 있어서 0.353만큼 높은 결과
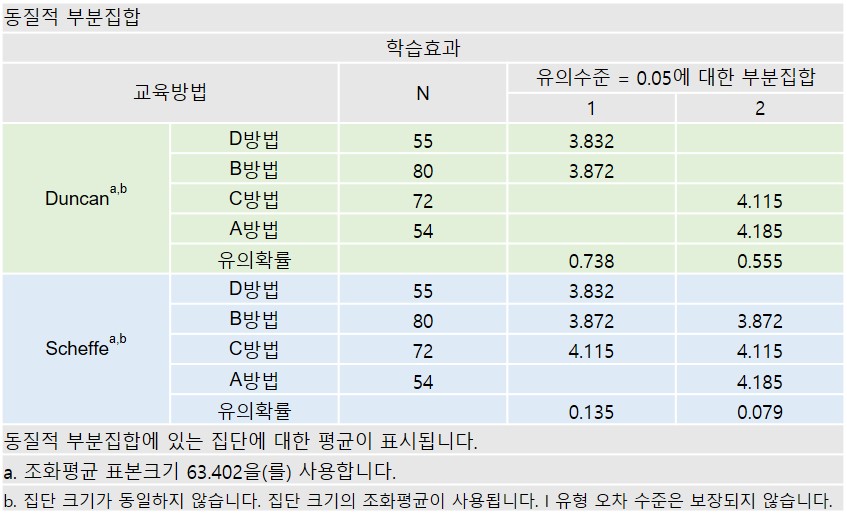
※동질적 부분집한은 유사한 집단(차이가 없는 집단)끼리 하나의 집단으로 그룹화.
유의수준 .05에 대한 1, 2의 집단으로 구분되어 차이가 있음을 의미.
Dunca 사후 검정 :
⇒ D,B는 1번, C,A는 2번에 속함 (B,D < A,C)
Scheffe 사후 검정 :
⇒ B, C는 1번과 2번 모두 속하여 D와 A에 유의한 차이가 없음
⇒ 1과 2에 모두 표시된다는 것은 두 집단에 모두 속할 수 있다는 것을 의미(D < A)
♣ 논문에 작성하는 방법
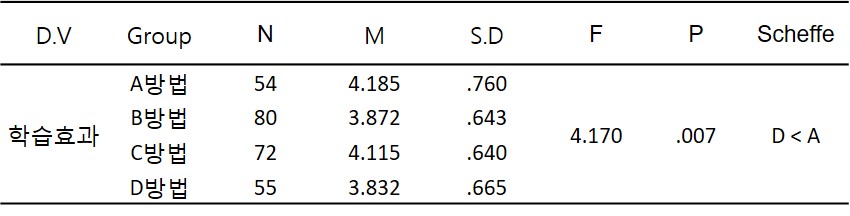
※ 사후분석의 표기는 학과, 학술지마다 다름
▣ 연구문제2. 식생활 습관에 따라 콜레스테롤은 차이가 있는가?
spss의 일원분산분석을 이용해 연구문제2에 대한 차이검증을 살펴보면,
• spss에서 분석 – 평균비교 – 일원배치 분산분석
∨옵션: 기술통계, 분산 동질성 검정 클릭
• 각 집단의 표본이 15명이기 때문에 정규성 검증 시행
• Shapiro-wilk test(n>30), kolmogorov-smirov test(n<30), 왜도와 첨도(2~4)
♣ 기본 분석 해석

• 식생활습관 중 육식이 혈중콜레스테롤이 가장 높음

• P>.05 : 분산이 동일
• P값이 0.873으로 유의수준 0.05보다 크기 때문에 등분산성 가정을 만족함

⇒ 식생활습관에 따라 혈중콜레스테롤에 차이가 있다
♣ 사후검정 해석
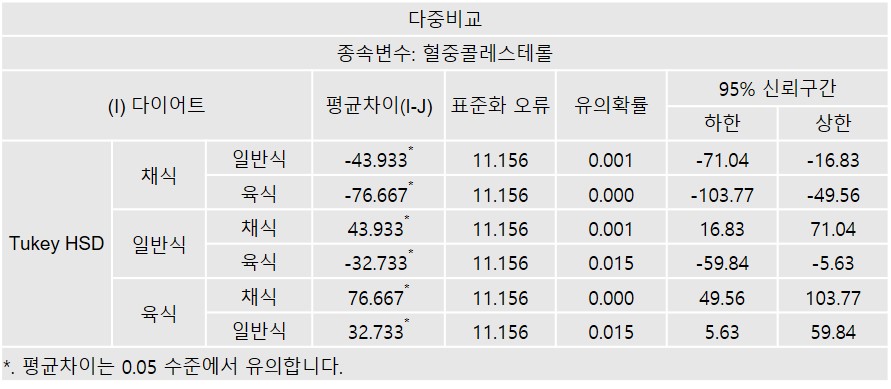
• 각 식생활습관의 간의 혈중콜레스테롤 차이는 모두 유의 (p<.05)

• Tukey와 Duncan 모두 같은 결과
• 식생활 습관에 따라 혈중콜레스테롤의 차이 비교 (채식 < 일반식 < 육식)
spss 일원분산 분석방법 및 해석작성법이 알고 싶다면 퀵데이터 논문통계 동영상으로 확인하기▶▶▶
"논문의 품질을 높이는 열쇠!!!
퀵데이터 논문통계분석을 통해 더욱 탄탄한 논문을 완성하세요."

퀵데이터 논문컨설팅은 논문 주제 선정부터, 연구모형, 통계분석, 심사 준비까지 전문 지도 박사님의 1:1 맞춤형 컨설팅 통해 효율적이고 빠른 논문작성을 도와드립니다. 논문 검토, 논문편집, 논문 통계분석까지 직접적인 컨설팅을 원한다면 퀵테이터에 문의하세요 상담문의 1600-7473

'논문자료 > 논문통계분석' 카테고리의 다른 글
| [논문통계] 이원분산분석 2편. spss를 이용한 상호작용효과 분석 및 해석하는 방법_논문통계강의_분산분석 정리 (0) | 2024.04.01 |
|---|---|
| [논문통계] 이원분산분석 1편. spss를 이용한 주효과 분석 및 해석하는 방법_논문통계강의_분산분석 정리 (0) | 2024.03.29 |
| [논문통계] 분산분석 2편_분산분석 계산방법_통계강의로 배우는 논문통계/퀵데이터 (0) | 2024.03.15 |
| [논문통계강의] 1. 분산분석(ANOVA)의 개념/분산분석이란?/분산분석 분류/논문통계분석_퀵데이터 (0) | 2024.03.13 |
| [논문통계] 3편. 확인적요인분석의 모델적합도 향상하는 방법_논문통계강의 (0) | 2024.01.18 |



